Annotation in Machine learning and Artificial intelligence
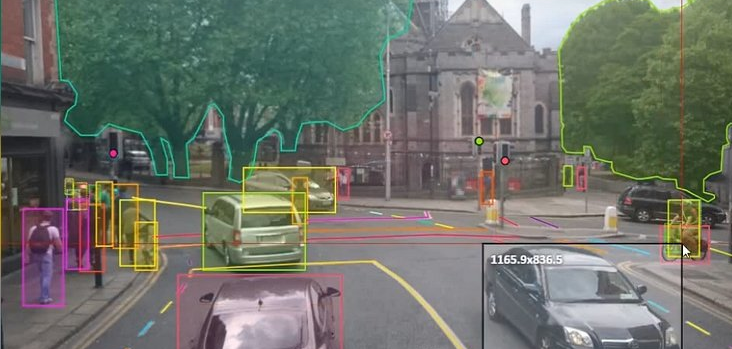
Data annotation is a critical process in machine learning and artificial intelligence where raw, unlabeled data is enhanced with labels or tags to make it usable for training machine learning models. This annotated data serves as the foundation for training algorithms to recognize patterns, make predictions, and perform various tasks. The process involves adding specific information or "annotations" to the dataset, which can include labels, bounding boxes, keypoints, or any other relevant information depending on the task at hand.
Here's an elaborate explanation of data annotation:
Types of Annotations:
Image Classification: Assigning labels to images indicating the presence of specific objects or characteristics.Object Detection: Drawing bounding boxes around objects of interest within images.Semantic Segmentation: Assigning labels to each pixel in an image to classify objects at a pixel level.Text Annotation: Labeling and categorizing text data for tasks such as sentiment analysis or named entity recognition.Audio Annotation: Labeling audio data for tasks like speech recognition or sound classification.Video Annotation: Annotating video frames for object tracking, action recognition, or scene understanding.Importance in Machine Learning:
High-quality annotated data is crucial for training accurate and reliable machine learning models.Annotated datasets help algorithms learn patterns, relationships, and features relevant to specific tasks.It ensures that the model generalizes well to new, unseen data by exposing it to a diverse set of examples during training.Tools and Techniques:
Data annotation can be a manual process performed by human annotators or an automated process using specialized tools.Common annotation tools include Labelbox, Supervisely, VGG Image Annotator (VIA), and more.Quality control measures, such as inter-annotator agreement, are often implemented to maintain annotation accuracy.Challenges:

Ensuring consistency among annotators is crucial for the reliability of annotated datasets.Large-scale annotation tasks can be time-consuming and expensive.Handling subjective or ambiguous cases requires clear guidelines and communication with annotators.Applications:
Data annotation is used in various industries, including healthcare (medical image annotation), autonomous vehicles (object detection for navigation), natural language processing (text annotation), and more.It plays a pivotal role in enhancing the capabilities of machine learning models across diverse domains.In summary, data annotation is a foundational step in the machine learning pipeline, shaping the quality and performance of models across a range of applications by providing the necessary labeled data for training and evaluation.